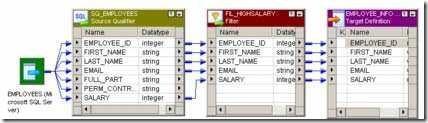
Transformation - Aggregator
Aggregator is an active transformation. Output from the aggregator can be different from input. Designer allows aggregator functions only in this transformation. Following types of function can be used
1. MIN
2. MAX
3. AVG
4. COUNT
5. FIRST
6. LAST
7. MEDIAN
8. PERCENTILE
9. STDDEV
10. SUM
11. VARIANCE
Along with these aggregate functions, you can use other row level functions such as IIF, DECODE etc.
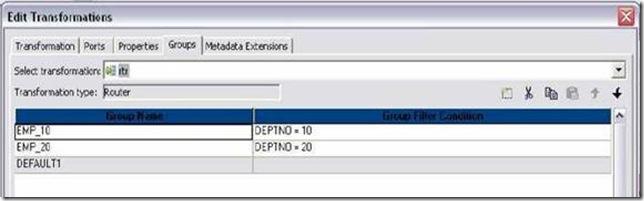
In Aggregator transformation, at least one port has to be selected as group by column. By default, aggregator will return the last value for a port ( if there are more than one record for group by column). Aggregator will also sort the data in ASC order on group by port.
NOTE: If primary column of the source is used in group by port, then aggregator will work as sorter transformation.
Nested Aggregate ports cannot be used in Aggregator. Means, you cannot get the count(*) in one port and use this value in other Aggregator port. This will invalidate the mapping.
Aggregator has a property SORTED INPUT. If you check this property, then aggregator assumes that data is coming in sorted order (on group by ports). If not, at run time session will fail. Sorted Input improves the aggregator performance.
Aggregator Transformation in Informatica
Aggregator transformation is an active transformation used to perform calculations such as sums, averages, counts on groups of data. The integration service stores the data group and row data in aggregate cache. The Aggregator Transformation provides more advantages than the SQL, you can use conditional clauses to filter rows.
Creating an Aggregator Transformation:
Follow the below steps to create an aggregator transformation
Go to the Mapping Designer, click on transformation in the toolbar -> create.
Select the Aggregator transformation, enter the name and click create. Then click done. This will create an aggregator transformation without ports.
To create ports, you can either drag the ports to the aggregator transformation or create in the ports tab of the aggregator.
Configuring the aggregator transformation:
You can configure the following components in aggregator transformation
Aggregate Cache: The integration service stores the group values in the index cache and row data in the data cache.
Aggregate Expression: You can enter expressions in the output port or variable port.
Group by Port: This tells the integration service how to create groups. You can configure input, input/output or variable ports for the group.
Sorted Input: This option can be used to improve the session performance. You can use this option only when the input to the aggregator transformation in sorted on group by ports.
Properties of Aggregator Transformation:
The below table illustrates the properties of aggregator transformation
Property
|
Description
|
Cache Directory
|
The Integration Service creates the index and data cache files.
|
Tracing Level
|
Amount of detail displayed in the session log for this transformation.
|
Sorted Input
|
Indicates input data is already sorted by groups. Select this option only if the input to the Aggregator transformation is sorted.
|
Aggregator Data Cache Size
|
Default cache size is 2,000,000 bytes. Data cache stores row data.
|
Aggregator Index Cache Size
|
Default cache size is 1,000,000 bytes. Index cache stores group by ports data
|
Transformation Scope
|
Specifies how the Integration Service applies the transformation logic to incoming data.
|
Group By Ports:
The integration service performs aggregate calculations and produces one row for each group. If you do not specify any group by ports, the integration service returns one row for all input rows. By default, the integration service returns the last row received for each group along with the result of aggregation. By using the FIRST function, you can specify the integration service to return the first row of the group.
Aggregate Expressions:
You can create the aggregate expressions only in the Aggregator transformation. An aggregate expression can include conditional clauses and non-aggregate functions. You can use the following aggregate functions in the Aggregator transformation,
AVG
COUNT
FIRST
LAST
MAX
MEDIAN
MIN
PERCENTILE
STDDEV
SUM
VARIANCE
Examples: SUM(sales), AVG(salary)
Nested Aggregate Functions:
You can nest one aggregate function within another aggregate function. You can either use single-level aggregate functions or multiple nested functions in an aggregate transformation. You cannot use both single-level and nested aggregate functions in an aggregator transformation. The Mapping designer marks the mapping as invalid if an aggregator transformation contains both single-level and nested aggregate functions. If you want to create both single-level and nested aggregate functions, create separate aggregate transformations.
Examples: MAX(SUM(sales))
Conditional clauses:
You can reduce the number of rows processed in the aggregation by specifying a conditional clause.
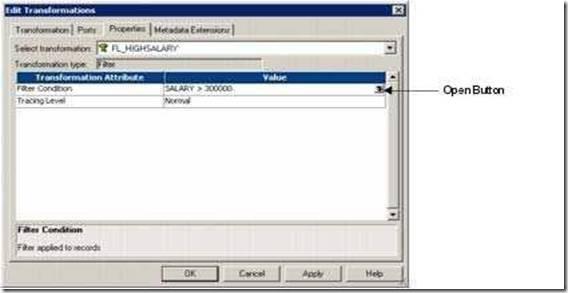
Example: SUM(salary, slaray>1000)
This will include only the salaries which are greater than 1000 in the SUM calculation.
Non Conditional clauses:
You can also use non-aggregate functions in aggregator transformation.
Example: IIF( SUM(sales) <20000, SUM(sales),0)
Note: By default, the Integration Service treats null values as NULL in aggregate functions. You can change this by configuring the integration service.
Incremental Aggregation:
After you create a session that includes an Aggregator transformation, you can enable the session option, Incremental Aggregation. When the Integration Service performs incremental aggregation, it passes source data through the mapping and uses historical cache data to perform aggregation calculations incrementally.
Sorted Input:
You can improve the performance of aggregator transformation by specifying the sorted input. The Integration Service assumes all the data is sorted by group and it performs aggregate calculations as it reads rows for a group. If you specify the sorted input option without actually sorting the data, then integration service fails the session.
Connected and Active Transformation
The Aggregator transformation allows us to perform aggregate calculations, such as averages and sums.
Aggregator transformation allows us to perform calculations on groups.
Components of the Aggregator Transformation
1. Aggregate expression
2. Group by port
3. Sorted Input
4. Aggregate cache
1) Aggregator Index Cache:
The index cache holds group information from the group by ports. If we are using Group By on DEPTNO, then this cache stores values 10, 20, 30 etc.
2) Aggregator Data Cache:
DATA CACHE is generally larger than the AGGREGATOR INDEX CACHE.
Columns in Data Cache:
Variable ports if any
Non group by input/output ports.
Non group by input ports used in non-aggregate output expression.
Port containing aggregate function
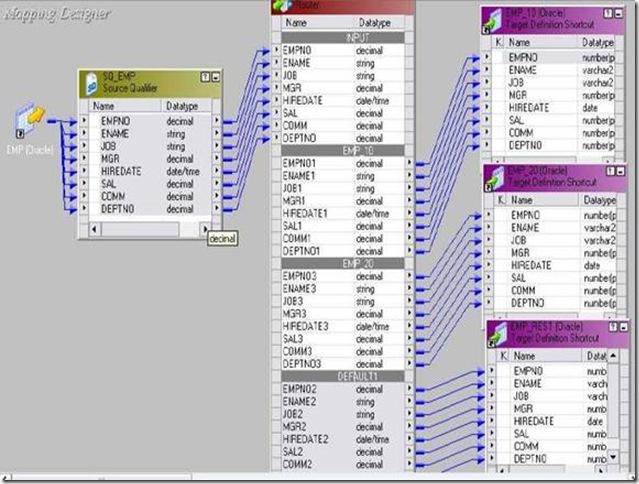
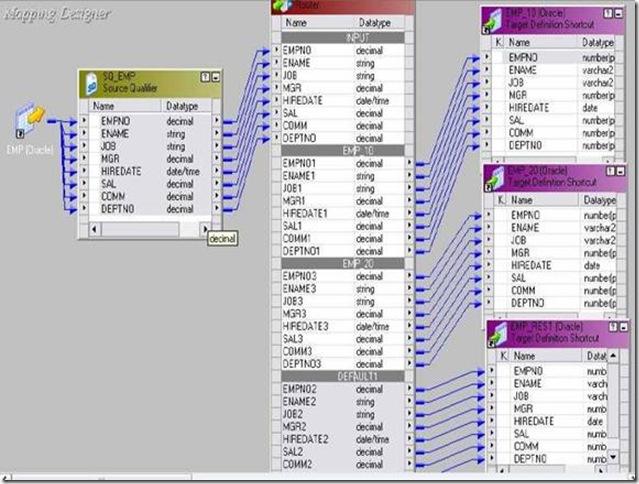
1) Example: To calculate MAX, MIN, AVG and SUM of salary of EMP table.
EMP will be source table.
Create a target table EMP_AGG_EXAMPLE in target designer. Table should contain DEPTNO, MAX_SAL, MIN_SAL, AVG_SAL and SUM_SAL
Create the shortcuts in your folder.
Creating Mapping:
1. Open folder where we want to create the mapping.
2. Click Tools -> Mapping Designer.
3. Click Mapping-> Create-> Give mapping name. Ex: m_agg_example
4. Drag EMP from source in mapping.
5. Click Transformation -> Create -> Select AGGREGATOR from list. Give name and click Create. Now click done.
6. Pass SAL and DEPTNO only from SQ_EMP to AGGREGATOR Transformation.
7. Edit AGGREGATOR Transformation. Go to Ports Tab
8. Create 4 output ports: OUT_MAX_SAL, OUT_MIN_SAL, OUT_AVG_SAL,
OUT_SUM_SAL
9. Open Expression Editor one by one for all output ports and give the
calculations. Ex: MAX(SAL), MIN(SAL), AVG(SAL),SUM(SAL)
10. Click Apply -> Ok.
11. Drag target table now.
12. Connect the output ports from Rank to target table.
13. Click Mapping -> Validate
14. Repository -> Save
Do's and Dont's while using Sorted Input in Aggregator transformation
In general, follow this check list to ensure that you are handling aggregator with sorted inputs correctly:
1. Do not use sorted input if any of the following conditions are true:
a.The aggregate expression uses nested aggregate functions.
b.The session uses incremental aggregation.
c. Input data is data driven.
You select data driven for the Treat Source Rows as Session Property, or the Update Strategy transformation appears before the Aggregator transformation in the mapping.
If you use sorted input under these circumstances, the Informatica Server reverts to default aggregate behavior, reading all values before performing aggregate calculations.
Remember, when you are using sorted inputs, you pass sorted data through the Aggregator.
Data must be sorted as follows:
1. By the Aggregator group by ports, in the order they appear in the Aggregator transformation.
2. Using the same sort order configured for the session.
If data is not in strict ascending or descending order based on the session sort order, the Informatica Server fails the session.
Questions:
1. What is aggregator transformation?
Aggregator transformation performs aggregate calculations like sum, average, count etc. It is an active transformation, changes the number of rows in the pipeline. Unlike expression transformation (performs calculations on a row-by-row basis), an aggregator transformation performs calculations on group of rows.
2. What is aggregate cache?
The integration service creates index and data cache in memory to process the aggregator transformation and stores the data group in index cache, row data in data cache. If the integration service requires more space, it stores the overflow values in cache files.
3. How can we improve performance of aggregate transformation?
Use sorted input: Sort the data before passing into aggregator. The integration service uses memory to process the aggregator transformation and it does not use cache memory.
Filter the unwanted data before aggregating.
Limit the number of input/output or output ports to reduce the amount of data the aggregator transformation stores in the data cache.
4. What are the different types of aggregate functions?
The different types of aggregate functions are listed below:
AVG
COUNT
FIRST
LAST
MAX
MEDIAN
MIN
PERCENTILE
STDDEV
SUM
VARIANCE
5. Why cannot you use both single level and nested aggregate functions in a single aggregate transformation?
The nested aggregate function returns only one output row, whereas the single level aggregate function returns more than one row. Since the numbers of rows returned are not same, you cannot use both single level and nested aggregate functions in the same transformation. If you include both the single level and nested functions in the same aggregator, the designer marks the mapping or mapplet as invalid. So, you need to create separate aggregator transformations.
6. Up to how many levels, you can nest the aggregate functions
We can nest up to two levels only.
Example: MAX( SUM( ITEM ) )
7. What is incremental aggregation?
The integration service performs aggregate calculations and then stores the data in historical cache. Next time when you run the session, the integration service reads only new data and uses the historical cache to perform new aggregation calculations incrementally.
8. Why cannot we use sorted input option for incremental aggregation
In incremental aggregation, the aggregate calculations are stored in historical cache on the server. In this historical cache the data need not be in sorted order. If you give sorted input, the records come as presorted for that particular run but in the historical cache the data may not be in the sorted order. That is why this option is not allowed.
9. How the NULL values are handled in Aggregator
You can configure the integration service to treat null values in aggregator functions as NULL or zero. By default the integration service treats null values as NULL in aggregate functions.
10. What can we do to improve the performance of Informatica Aggregator Transformation?
Aggregator performance improves dramatically if records are sorted before passing to the aggregator and sorted input option under aggregator properties is checked. The record set should be sorted on those columns that are used in Group By operation.
It is often a good idea to sort the record set in database level. e.g. inside a source qualifier transformation, unless there is a chance that already sorted records from source qualifier can again become unsorted before reaching aggregator.
11. Under what condition selecting Sorted Input in aggregator may fail the session
If the input data is not sorted correctly, the session will fail.
Also if the input data is properly sorted, the session may fail if the sort order by ports and the group by ports of the aggregator are not in the same order.
12. What is aggregate cache in aggregator transformation?
The aggregator stores data in the aggregate cache until it completes aggregate calculations. When u run a session that uses an aggregator transformation, the informatica server creates index and data caches in memory to process the transformation. If the Informatica server requires more space, it stores overflow values in cache files.